Introducing RadPod: Deep Research for Your Data
Knowledge workers are on the cusp of a new era of AI-enhanced super-productivity enabled by rapidly improving large language models (LLMs), e.g. GPT-4 (ChatGPT). Some have called AI the new electricity that will have an impact similar to the industrial revolution.
Software engineering is already in a period of transition, with LLMs crushing coding competition benchmarks and AI users observing significant productivity boosts. This new generation of AI can do real work.
The mission of RadPod is to help other knowledge workers ride the wave of the latest advances in AI to make work more enjoyable and productive. While base LLMs like GPT-4 (powers ChatGPT) are incredibly powerful, they lack the context of your work and only know about data they've seen in training. A major gap in current AI offerings is that bringing your data to LLMs is hard, and doesn't work well enough.
With RadPod, we focused on making it easy to bring your possibly large data to Pods and get the highest quality answers using our cutting-edge technology, which we call Reasoning Agents over Data (RAD).
Reasoning Agents over Data
A base LLM is trained to generate responses, one word (or token) at a time given previous words. They can be "prompted" with an input to which an output, or response is generated. When given hard prompts, like a difficult math problem, an LLM can struggle to produce the correct answer.
"Reasoning" models such as OpenAI's o1/o3 and DeepSeek's R1 use a technique called, "chain-of-thought" or "test-time compute" that encourages the LLM to first "show the work", or reasoning, before giving a final answer. Just like humans, LLMs benefit from using some scratch space to jot down notes, leading to much higher-accuracy on reasoning tasks like math problem-solving and programming. Furthermore, the more compute used in this fashion, the higher the accuracy.
At RadPod, we employ similar test-time, reasoning techniques on top of state-of-the-art LLMs (we use an ensemble of models from OpenAI, Anthropic, Google, and the best open-source adapted models) to give higher-quality answers, but optimize further by imbuing the LLM with tools (e.g. code generation and execution) it can use in our custom environment, the Pod.
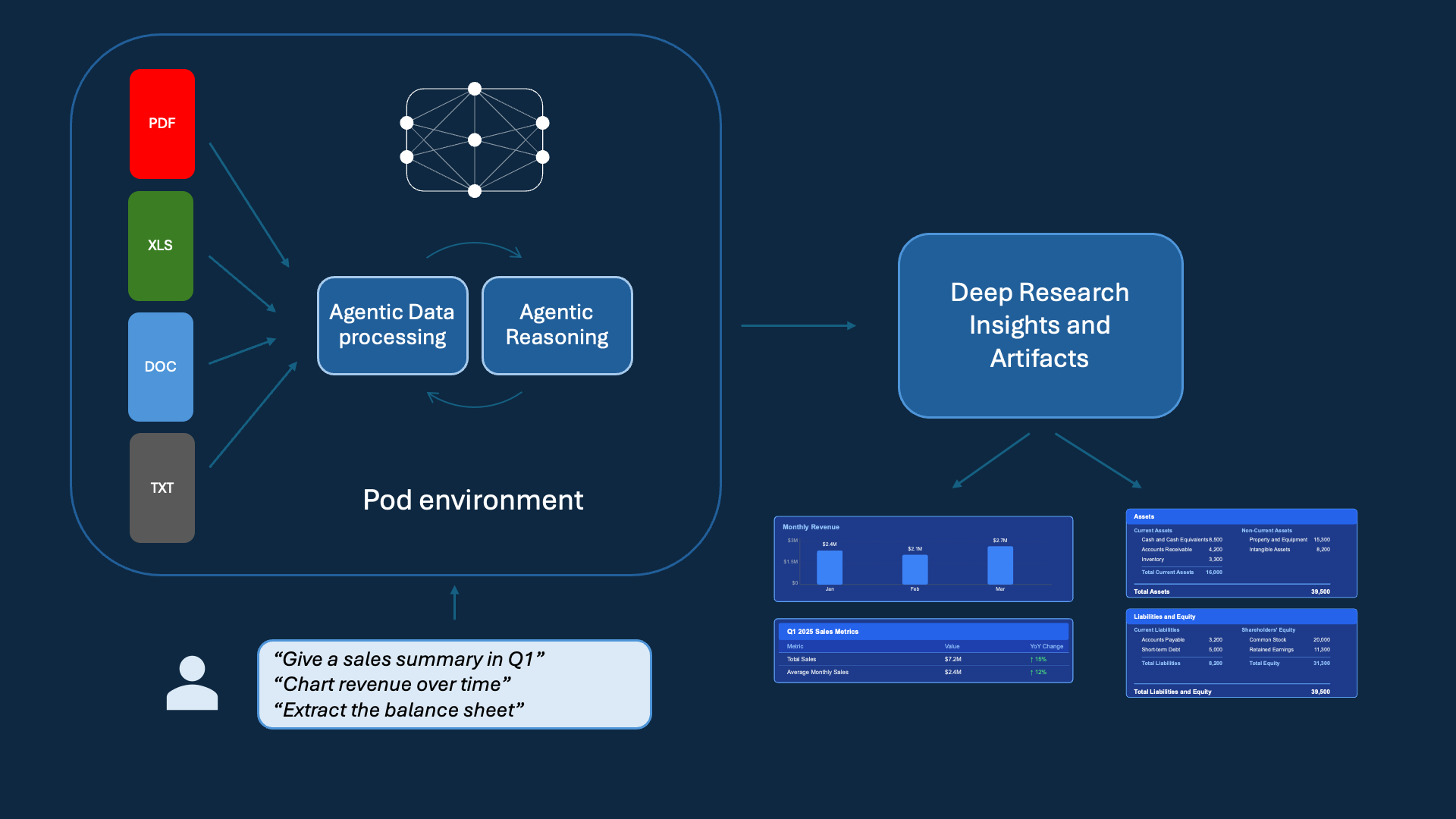
The Pod Environment
The Pod is the workspace in which our RAD AI agents collaborate with you to help you get work done. You define the Pod by adding your data, which is treated as a first-class citizen, and which the agent can see and reason over. This context is important for the agent to understand your work tasks. Think of RadPod as a smart co-worker who can deep dive into data, write complex data pipelines, and run analyses to answer your hard natural language questions.
These pipelines traditionally involved multiple technical employees and/or teams to carry out requests for answering business questions. With RadPod, you simply add your raw data in its native format (e.g., PDFs, spreadsheets) and start making natural language requests to receive immediate answers. The AI is able to write code and execute it when it makes sense, which is often the case when dealing with large amounts of data. Furthermore, this code is highly parallelized, so that execution time is reasonable. What may have previously taken hours can be accomplished in seconds.
Handling Large Datasets with High Accuracy
Unlike base LLMs (GPT-4 has 128k context), RadPod can handle infinite context, which is why we don't have a limit on the number of files that can be uploaded to a pod. For example, in the FinanceBench pod we have real financial statements like 10Ks of public companies, comprising more than 300 pdfs, with 51 thousand pages, and 40 million tokens. Yet we're able to answer questions, such as those found in the FinanceBench benchmark with high accuracy.
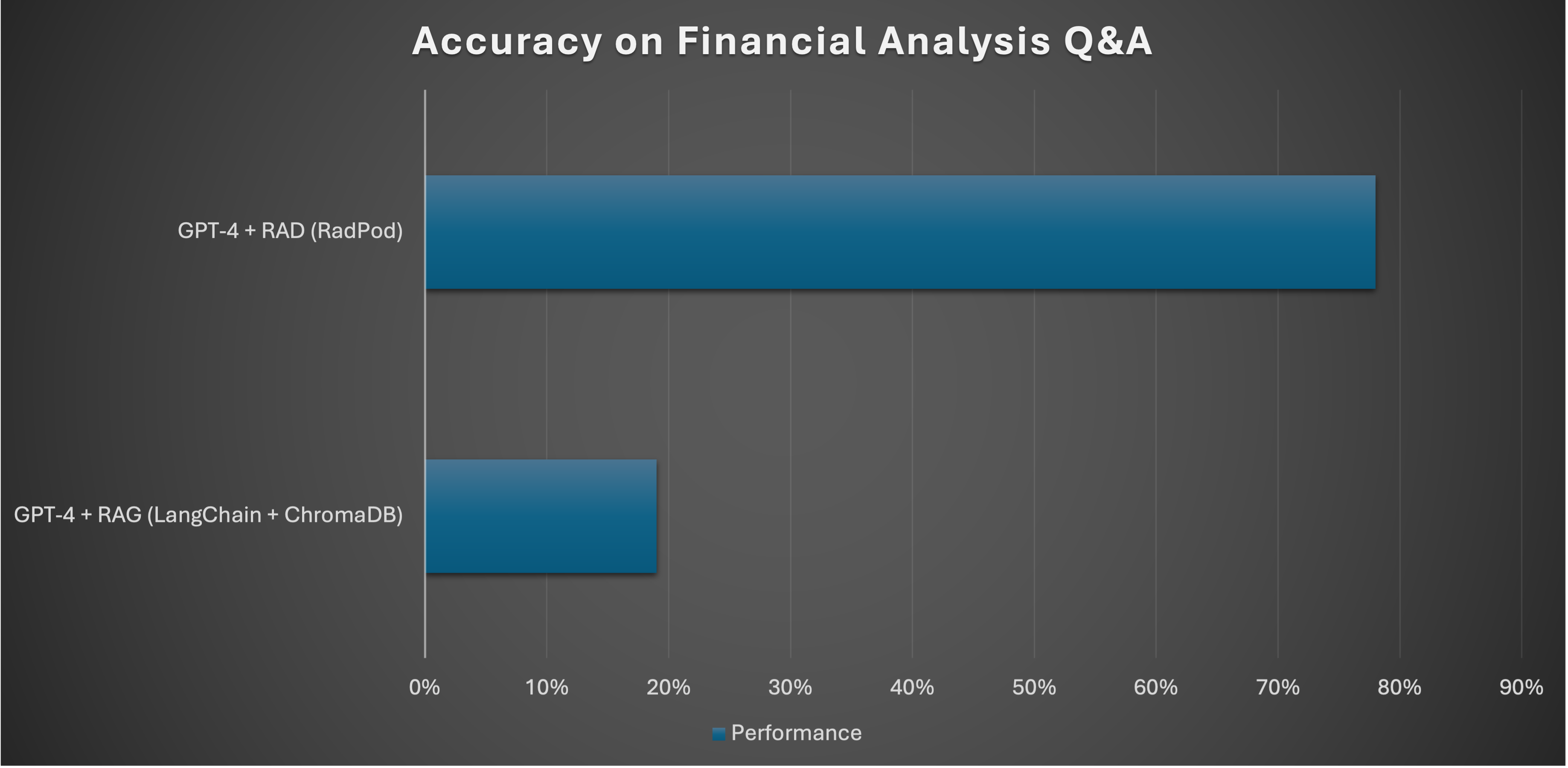
As a comparison, a common way to handle a lot of context is to use a technique called Retrieval-augmented generation (RAG) when there is too much data to fit in an LLM's context. The idea is to first retrieve query-relevant documents and put as much in the context. We found when properly benchmarked on realistic questions, standard RAG implementations perform quite poorly in comparison. On an internal benchmark using questions from FinanceBench, a dataset of realistic Q&A examples for financial analysis, standard RAG implementations achieve less than 20% accuracy, whereas with the same base model (GPT-4), RAD achieves 80% accuracy. We continuously update the base models we use in RAD agentic framework, and have seen significant improvements replacing GPT-4 with more recent, stronger ones. The difference in accuracy is quite palpable when experienced in a live product like RadPod.
| Features | RAD (Our Approach) | RAG | Standard long-context LLMs |
|---|---|---|---|
| High Accuracy | ✓✓ | ✗ | ✓(within context) |
| Unlimited Context | ✓ | ✓ | ✗ |
| Adaptive Compute for Better Answers | ✓ | ✗ | ✗ |
Citations You Can Trust
While LLMs often produce stunningly good outputs, occasional hallucinations (the LLM making stuff up out of thin air) are a known issue. In RadPod, we expect answers to be grounded in the data in the Pod, and seek to produce the most trustworthy answers that are easy to verify. If the time to verify an answer is longer than doing the work yourself, productivity gains can be marginal or negative. Our solution involves citations that not only cite the sources, but also provides the context and location from which the answers are produced. We found this to be much easier to trust than source-only citations (which in other products often do not provide supporting evidence), and even improves reliability of the answers.

Top Research Team
RadPod is a product of Twenty Labs, a US-based team of top engineers and researchers hailing from Google DeepMind, and Microsoft AI, with pioneering research in language models and bringing generative AI to market. We are dedicated to making cutting-edge research accessible to all and ensuring RadPod remains at the forefront of AI through in-house, product-driven innovation, with all data securely stored and processed in US data centers.
Learn More and Dive In
Learn more by checking out key features, example use-cases, and Spotlight Pods with preloaded datasets. Then try it for yourself in the free tier, with no obligations or credit card required. We are just scratching the surface of what is possible in RadPod with many more features coming soon.